Errant: The Kinetic Propensity of Images is a project about the automatic analysis and visualization of motion in the cinema. It consists of a two-channel video projection. The following video shows the two channels, and is best viewed in full screen.
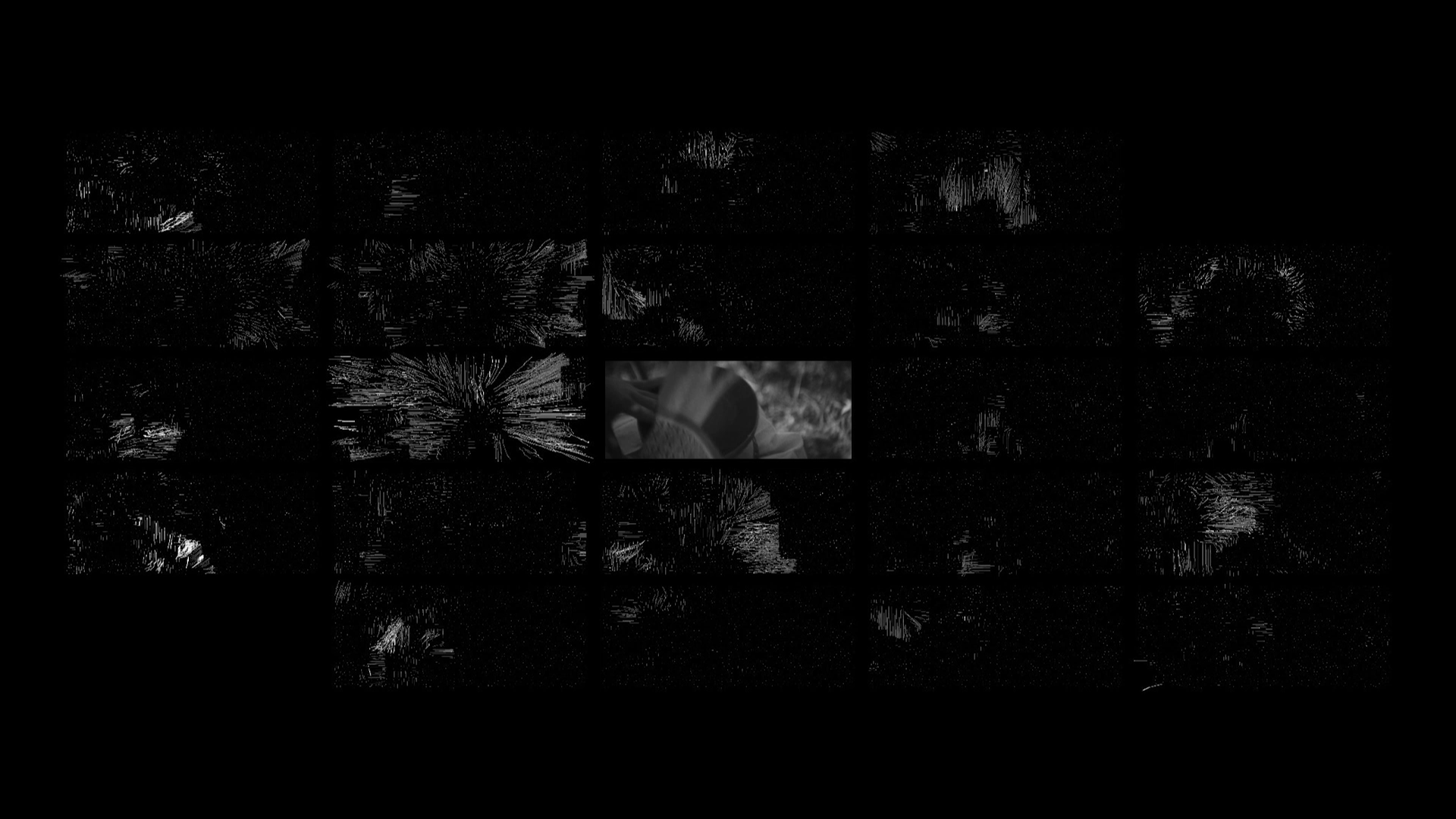
The left channel shows the decomposition of the optical flow of a shot into basic motion patterns. These motions are extracted using unsupervised machine learning methods.
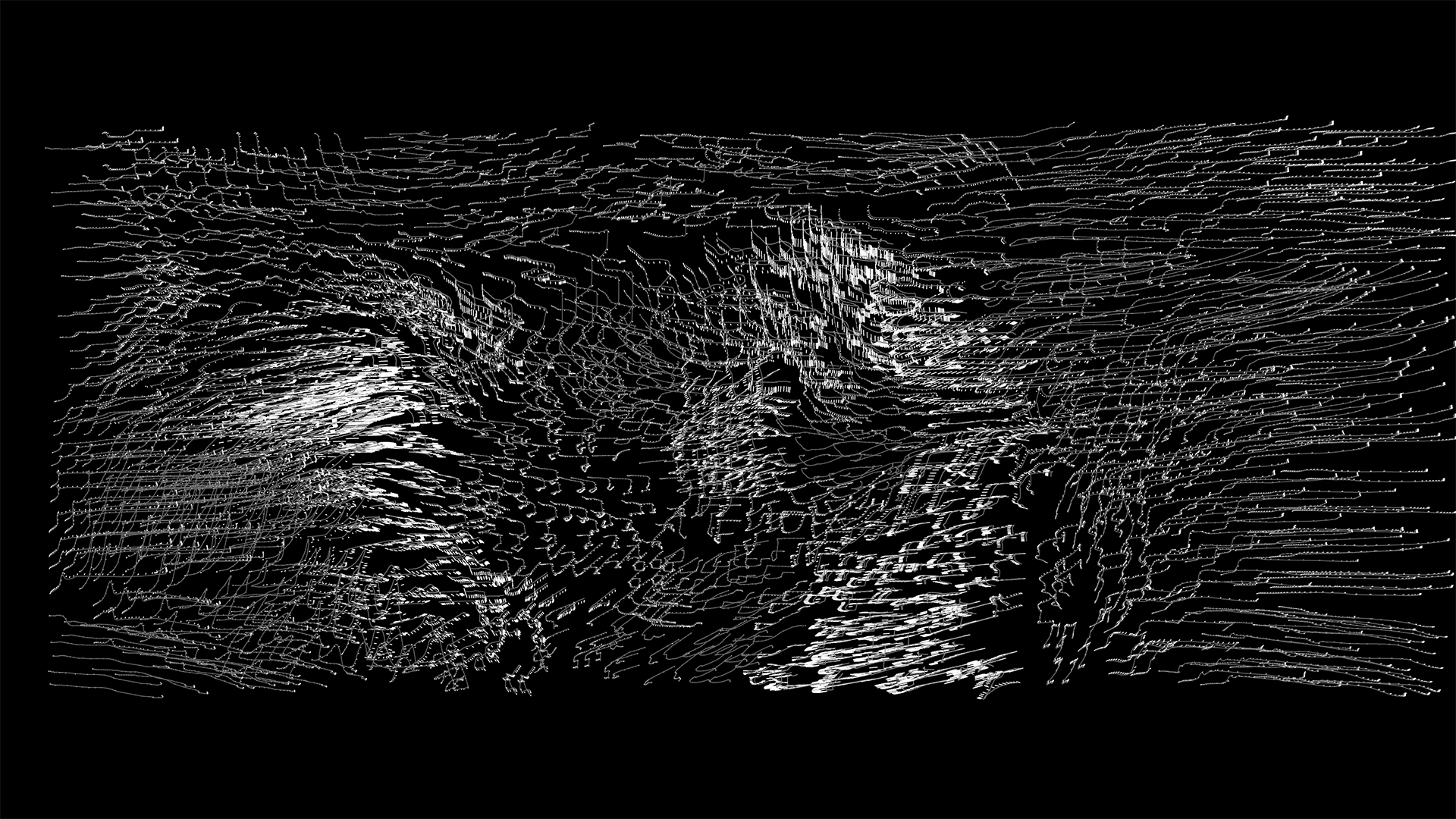
It is possible to reconstruct approximately the original shot's optical flow by combining those latent motions. The right channel shows the reconstruction of the optical flow.
The material consists of three films directed by King Hu 胡金銓:
A Touch of Zen 俠女 (1971)
Legend of the Mountain 山中傳奇 (1979)
Raining in the Mountain 空山靈雨 (1979)
King Hu’s work is important because of: its strongly balletic quality; its tendency to foreground and sometimes deconstruct classical Chinese culture; and its commitment to criticizing state power and surveillance.
The following documentation gives an overview of the project:
This work was commissioned by Linda Lai for the exhibition Algorithmic Art: Shuffling Space and Time, held at the Hong Kong City Hall, December 27 2018 - January 10 2019.
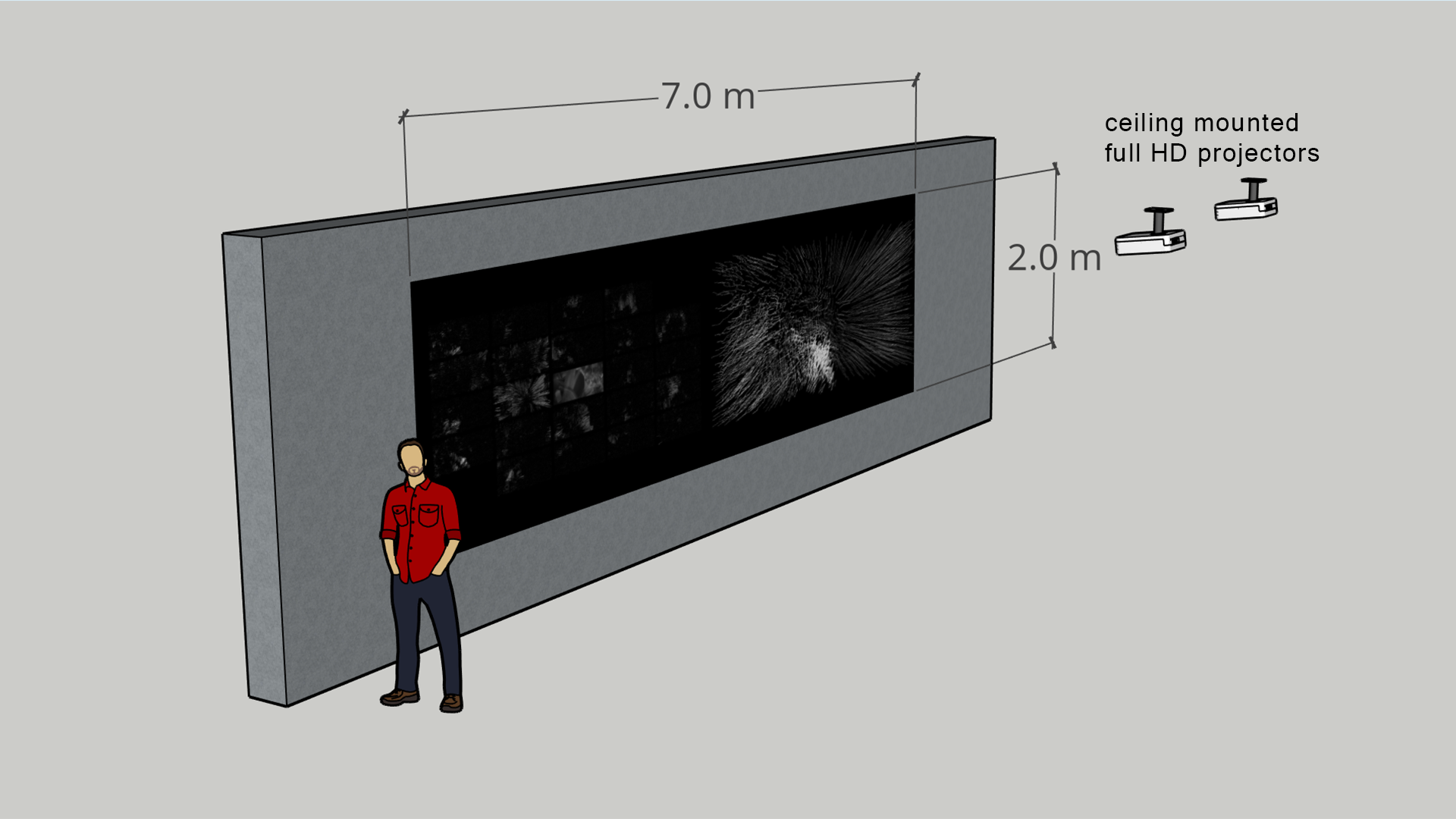
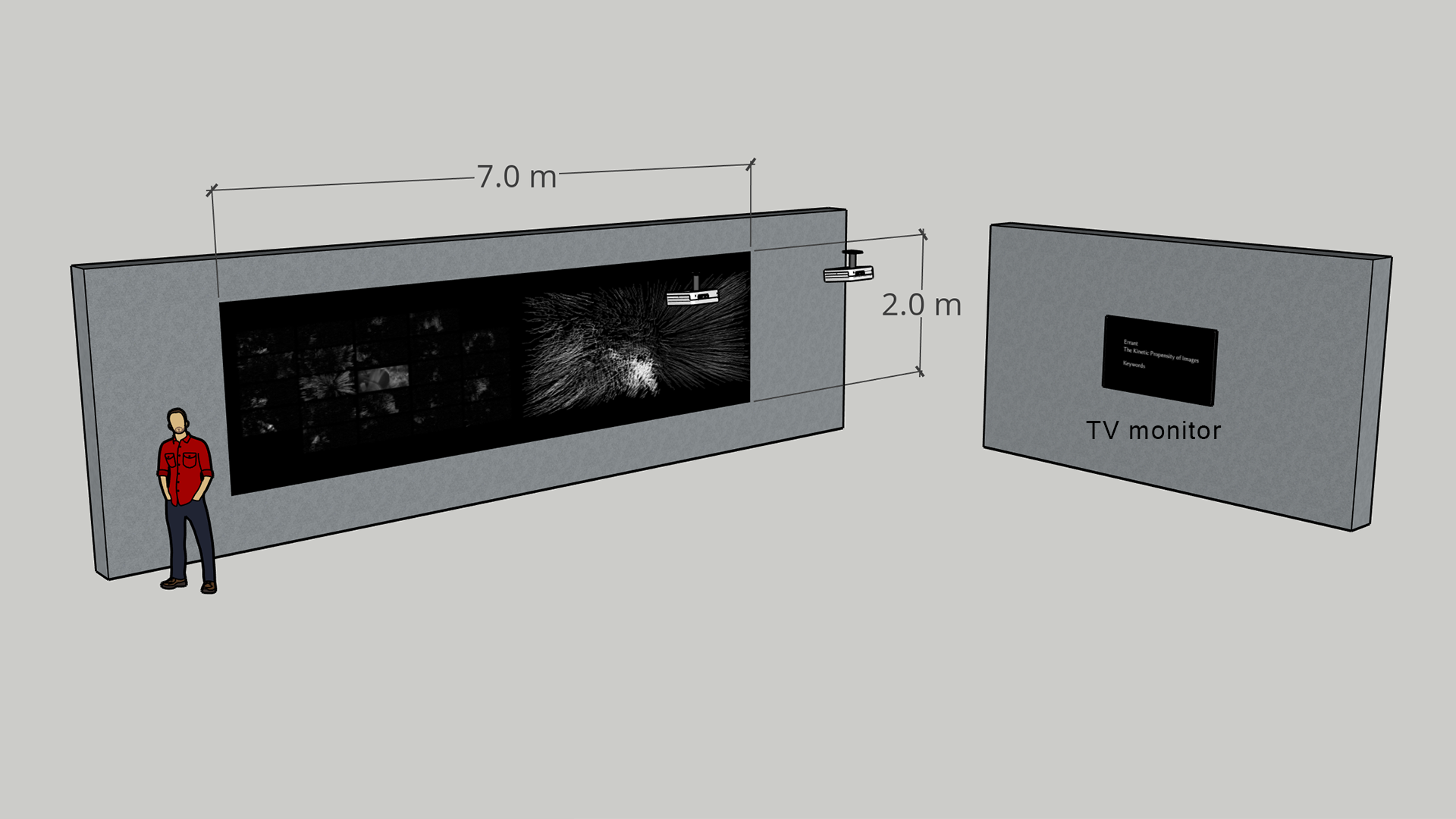
The following image shows the setup in the show.
Production of this work was partly funded by a City University of Hong Kong Strategic Research Grant, project no. 7004992.
It was also made possible by a research fellowship granted by the School of Creative Media's Center for Applied Computing and Interactive Media (ACIM) for the 2018-19 academic year. Many thanks to ACIM co-directors Richard Allen and Jeffrey Shaw for their support of this project.
MOTIVATION
Most film analysis and criticism describe movement in cinema by reference to the object that moves. Descriptions of scene motion typically focus on the nature of the moving object (whether it is a person, a car, etc.), its velocity, and perhaps certain aspects of its rhythm. Descriptions of global motion mainly focus on the camera as the source of that motion. Writers characterize camera movement as, for instance, a “pan”, “tilt”, “track”, “dolly”, “zoom”, etc. These terms presuppose a privileged object, the camera, as the source of the visible movement. The conventional vocabulary of critical analysis guides the expectations of the critic or theoretician, who sees only what they expect to find, and they expect to find only that for which they have acquired words. Writers on cinema almost invariably presuppose a mobile camera viewing mobile objects in a three-dimensional world. In other words, the focus is on the causes or sources of the movement rather than on its visible quality. Under these conditions, we lack the resources to describe or represent the phenomenological quality of motion in the cinema.
Our awareness of movement in mainstream films, advertisements and so on is typically bound to specific objects and locations in support of story content. Viewers do not typically attend to the visual qualities of movement itself. Our attention is directed to what is moving, not how it moves. In opposition to this dominant approach, this project aims to focus deep perception on motion. Its aim is, moreover, not purely formal. It embodies a reaction against the denigration of close attention that accompanies the “attention economy,” the commodification of attention in which we are currently immersed, and provides a medium for cultivating and enriching the content and manner of sense perception. In other words, the algorithm developed in this project makes movement perceptually salient as an end in itself.
A shot or sequence in a film often contains several on-screen motions, for instance the movements of different people, as well as the effects of the camera motion. The organization of movement is a crucial aspect of cinematic art. Whenever we focus our attention on the narrative information, we fail to notice the organization of movement in those films. In opposition to this dominant emphasis on the communication of narrative information, this project aims to focus deep perception on motion.
The philosophical and conceptual aspects of this work are mediated by an awareness of computational technology. In particular, the methodology employed here relies on unsupervised machine learning to produce a visual dictionary of motion patterns.
The latent components need not correspond to the conventional categories of cinematic criticism and analysis. The algorithm is not “trained” by exposure to already known examples or “model answers” that embed familiar ways of understanding motion. Rather, the algorithm extracts those latent motions for each shot in the movie in an unsupervised way by applying optimization techniques.
We can think of the use of machine learning in this work as a way to help viewers "unlearn" stereotypical ways of seeing and understanding movies, and sensitizing them to certain qualitative aspects of motion in the cinema.
ALGORITHM
The input to the procedure consists of one or more movie sequences available in digital form, as a sequence of jpg images (frames). Each image is 960 x 408 pixels. The material has segmented into shots. Every image is considered to be grayscale, so color is ignored.
The following steps are performed for every shot in the database.
1. Optical flow estimation
So-called optical flow techniques receive a video clip as input and estimate the movement depicted in every pair of consecutive frames in that clip. This estimation involves assigning a motion vector to every pixel (or region of pixels) in the first image. A motion vector can be visualized as an arrow. Its orientation represents the direction of the movement depicted in that pixel. Its magnitude represents the apparent speed of the motion. The following images show a short movie excerpt together with the matrix of vectors that represent the movement visible in every pair of consecutive frames in that excerpt.
The Coarse2Fine Optical Flow algorithm, designed by Thomas Brox et al, is used to compute the optical flow between every pair of subsequent frames.(1) If the shot has m frames, we obtain m–1 flow fields. The flow over a grid of overlapping flowpoints. Each flowpoint is about 60 x 60 pixels. The width separation is 30 pixels. The height separation is 22 pixels. This separation ensures a fixed grid of 32 x 18 flowpoints.
2. Factorization
Decompose the optical flow for an entire segment using non-negative factorization. The algorithm requires that data should be nonnegative, but motion vectors typically contain negative data. The solution adopted here represents every flow vector (x, y) as a quadruple of non-negative numbers (x+, x-, y+, y-). For instance, the vector (3, -2) is represented as (3, 0, 0, 2).
Form a matrix V of dimensions n x m, where n is the number of flow vectors per frame times four, and m is the number of frames in the shot. This matrix is the input to the factorization algorithm.
Perform projective non-negative factorization on V by searching for a matrix W that minimizes
|| V – W WTV ||F(1) W is a non-negative matrix of dimensions n x k, where k < min(n,m). We use an algorithm proposed by Yuan and Oja."(2)
The minimization algorithm expects a number k and an initial estimate of W. To compute both inputs automatically, we perform a PCA on V, i.e., we obtain the eigenvectors and eigenvalues of the covariance matrix of the column vectors in V. The number k is then obtained by thresholding the rate of decay of the eigenvalues. The first k eigenvectors are then selected as the initial estimate of W.(3) To ensure non-negativity, all negative components of the eigenvectors are set to zero. Once the number of factors and the initial estimate are known, the projective non-negative factorization algorithm minimizes (1) iteratively until convergence.
The resulting W can be interpreted as a dictionary of (approximately orthogonal) components. WWT can be interpreted as akin to a projection matrix. H = WTV can be interpreted as a matrix of mixing coefficients or weights. WH = WWTV is the reconstruction of V using the dictionary W.
A sequence often contains complex movements involving various characters as well as the camera. Even a simple case, that of a camera viewing an empty corridor with a wide angle while tracking forward, may be kinetically quite complex if the layout of the scene contains many objects distributed from the foreground to the background. To capture this potential complexity, it is helpful to cluster the latent motion components. We can think of each cluster as a smaller dictionary or sub-dictionary for this sequence. To do this, we perform another projective non-negative matrix factorization on HT in order to obtain a new basis matrix W'. We now look at each column j in the mixing coefficient matrix W’ THT. Let i be the row with the max entry in the j-th column. Assign the j-th dictionary entry to the i-th cluster. Suppose we obtain k’ latent components. We will form k’ matrices W1 , W2 , ……, Wk' . Matrix Wi contains the elements of W assigned to the i-th cluster.
3. Projection
We approximate the optical flow fj of the j-th frame in the sequence using the i-th basis matrix Wi as
fj,i = Wi WiTfj .
It is now possible to render the decomposition of each frame in a sequence using each separate matrix, in order to visualize the dynamic components of the sequence. If there are, for instance, 30 sub-dictionaries, we can visualize 30 different reconstructions of the movement. Each reconstruction responds to a different aspect of the movement of the sequence. These are the images shown in the left video channel of the installation.
The right channel of the installation shows the reconstruction WH of the frame using the entire dictionary.
4. Visualization
The flow is visualized using streaklines, a visualization and analysis technique often used in fluid dynamics to represent unsteady (time-varying) flows.(4)
We first identify a set S of keypoints (corners) in the first frame of the shot being analyzed. We associate a virtual particle with each key point. Using the optical flow data that we wish to visualize, each these virtual particles is advected through the video sequence.
In every frame, a new particle is placed in each of the original keypoints in S and advected through the rest of the sequence. If a sequence consists of m frames and p keypoints, (m – 1) x p particles will be generated.
A streakline at time t is the locus of the positions at t of all virtual particles that started from the same initial keypoint.
This visualization method is used for the separate components (left channel of the installation) and for the complete reconstruction (right channel).
5. Matching Motion Patterns
In addition to the main installation, this project also includes Errant/Gestus, a video that juxtaposes similar motion patterns extracted from the films of King Hu. This section explains the technical procedure that generated this video.
Every movie in the database is divided into segments of constant length (in this case, 10 frames). The distance between two segments A and B consisting of frames A1 , A2 , … and B1 , B2 , … is measured as follows.
Let WA and WB be the dictionaries for the shots that contain the segments A and B respectively. These dictionaries are constructed using the method explained in section 2 above. Note that different dictionaries need not have the same lengths (number of columns). Let LA and LB be the lengths (number of columns) of the two dictionaries.
For every frame Ax and Bx two Euclidean distances are computed, first between the normalized projection coefficients WATAx / LA and WATBx / LB and, secondly, between WBTAx / LA and WBTBx / LB . The two distances are averaged, to produce a single value for the distance between frames Ax and Bx. Then the distances across all pairs of corresponding frames in A and B are added, and the result is taken as the measure of the distance between A and B.
For every segment, its closest matches are those segments with the smallest distance to it. To make the final nine-image video, eight closest matches are selected. The template is shown in the center of a nine-cell grid with its closest matches arranged around it. This approach can be seen as an updated version of the earlier Hector Rodriguez project Gestus: Judex.
_____________
(1)
Thomas Brox, Andres Bruhn, Nils Papenberg, and Joachim Weickert, “High Accuracy Optical Flow Estimation Based on a Theory for Warping,” In T. Pajdla and J. Matas (Eds.). Computer Vision – ECCV 2004. Lecture Notes in Computer Science, Vol. 3024, Springer, Berlin, pp. 25–36, 2004. The implementation used in this project is the Python Dense Optical Flow: https://github.com/pathak22/pyflow
(2)
For a description of the projective non-negative matrix factorization method, see: Yuan Z., Oja E. (2005) "Projective Nonnegative Matrix Factorization for Image Compression and Feature Extraction." In: Kalviainen H., Parkkinen J., Kaarna A. (eds) Image Analysis. SCIA 2005. Lecture Notes in Computer Science, vol 3540. Springer, Berlin, Heidelberg. https://link.springer.com/chapter/10.1007/11499145_35
(3)
Zhirong Yang, Zhanxing Zhu, and Erkki Oja, "Automatic Rank Determination in Projective Nonnegative Matrix Factorization", in V. Vigneron et al. (Eds.): LVA/ICA 2010, LNCS 6365, pp. 514–521, 2010.
(4)
For a description of streaklines and an example of their application to computer vision, see: Mehran R., Moore B.E., Shah M. (2010) A Streakline Representation of Flow in Crowded Scenes. In: Daniilidis K., Maragos P., Paragios N. (eds) Computer Vision – ECCV 2010. ECCV 2010. Lecture Notes in Computer Science, vol 6313. Springer, Berlin, Heidelberg. https://link.springer.com/chapter/10.1007/978-3-642-15558-1_32.
SETUP
There is one single file to be spanned over two projectors. It should be played as a loop.
Video format: mp4 file compressed with H.264.
Video length: 30 min 43 sec.
Projector specs: Minimum 3000 ANSI Lumens.
Minimum dimensions of the projection surface: 7000mm width x 2000mm height.
Setting: a completely dark room.
The work was exhibited at Hong Kong City Hall using a QuickTime Player on a macbook pro connected to two projectors via HDMI cable and thunderbolt adapters.
It is optional to show the documentation video on a TV monitor.
Installation images
The following video footage was taken by Alex Ngan during the premiere of the work as part of the Algorithmic Art: Shuffling Space and Time exhibition organized by Linda Lai at the Hong Kong City Hall.