THE LUCAS KANADE ALGORITHM
LK is only one of several optical flow algorithms widely used in computer vision. Optical flow methods aim to align two images, a task frequently described in the technical literature as “image registration”. A typical image registration task is motion tracking. That is, given two frames A and B in a movie, we want to detect the motion of any object from A to B (Figure 1).

[ Figure 1 ]
To appreciate the internal logic of image registration algorithm, it is necessary to recall a few fundamental concepts:
- Every image consists of a two-dimensional array of pixels.
- Each pixel is uniquely identified by an ordered pair of numbers (x, y) that give its location on the image.
- One of the main properties of a pixel is its brightness.
LK starts out from the assumption that clusters of contiguous pixels move together as a whole from one image to the next. Thus the procedure defines a set of subregions or what I call “flowpoints” in the image (Figure 2). This initial stipulation requires assigning values to several parameters. These include the size of each flowpoint and the distance between them. A typical size might be 5 x 5 pixels. The flowpoints can also be tightly packed together or be located far from one another.


[ Figure 2 ]
The objective of the algorithm is to align each flowpoint (or "template") in Frame A with some matching subregion in Frame B.[1] For every template, LK aims to determine where it has moved in the next image (Figure 3).
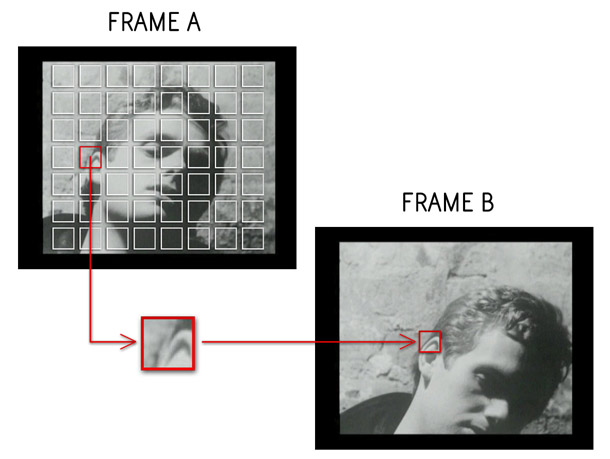
[ Figure 3 ]
Suppose that one flowpoint has moved 50 pixels along the x axis and 60 along the y axis. This displacement along two directions constitutes the motion vector for that flowpoint.
The aim of the algorithm is to identify a likely motion vector for every flowpoint in Frame A. The word "likely" is important here. The algorithm is not guaranteed to identify the correct motion vector in every case. It only gives a hypothetical estimate. This procedure yields probable matches rather than certain results.
What is the criterion that a probable match has been found? Recall that the most important property of a pixel is its brightness. It would make sense to postulate that two subregions of two frames are perfectly aligned when the brightness of each corresponding pixel is identical. But such a perfect match is unlikely to happen, so a more realistic measure would look for cases when the difference in brightness across all corresponding pixels of the two subregions is “small enough”, i.e., when it falls below a certain threshold set by the programmer. This indicates that corresponding pixels in the two subregions are “close enough” to one another.
A match between two regions occurs when the error between the template and the target falls below a threshold. The goal of image registration, then, is to minimize the error between the pixels of the template and those of the target.
This criterion not only specifies the conditions under which a match occurs but also, and more importantly, gives a measure of the error or disparity between two subregions. The greater the brightness difference, the greater the error[2]. This criterion thus measures the disparity between the template and the target.
The search for a match performs the same iterative procedure on each flowpoint (“template”) in Frame A. The procedure begins with a hypothesis about where the template might have moved in Frame B. The program then computes the error between the template and the target in this hypothetical location. If the error falls below the specified threshold, the algorithm then assumes that a match has been found. Otherwise, it looks for a match in another location of Frame B.
The algorithm continues searching in this way until completing a specified maximum number of iterations, an important parameter whose value is selected by the programmer. Suppose that we set a maximum of twenty iterations. After attempting unsuccessfully to locate a match twenty times, the algorithm simply gives up and tries to match the next flowpoint.
How does the algorithm look for a probable match in Frame B? Suppose that the template is 5 x 5 pixels in size. One possible method would involve comparing it against every 5 x 5 subregion of Frame B and then selecting the one that yields the smallest error. This procedure would therefore involve an exhaustive search through the space of all possible hypotheses.
This method, while simple to understand and implement, presents two drawbacks. First of all, its implementation would in most cases be hugely inefficient, since time would often be wasted comparing the template against subregions of Frame B where the pixels are unlikely to have moved. This method therefore makes no sense in time-critical applications. Secondly, and most importantly, this method is extremely crude, because it fails to learn from its mistakes. This approach does not attempt to refine or improve each successive hypothesis. It looks mechanically through every possible hypothesis. Even if a super-computer could make such a brute force method practical for most applications, it would still be cognitively crude.
At each iterative step the value of the error is computed, and this error yields a measure of how incorrect the hypothesis is. This information can be used to direct and improve its search by generating a better hypothesis in the next step. This improved method, which is the essence of the LK approach, makes each iteration propose a new hypothesis whose error is smaller than that of the previous hypothesis. Each hypothesis is thus measurably better than the preceding one, and so the algorithm proceeds by constantly refining its hypotheses.
Every loop starts out by hypothesizing that the flowpoint has not moved at all from Frame A to Frame B. Thus the algorithm computes the error measure between the same subregions of two images. For instance, if the left top corner of the 5 x 5 flowpoint is located at pixel (24,120) in Frame A, LK will attempt to match it against the 5 x 5 subregion located at pixel (24, 120) of Frame B. If the attempted match fails, the algorithm then uses spatial gradient information to update its hypothesis in a direction that will tend to reduce the error. Thus the method repeatedly hypothesizes a possible motion vector, then computes the error by comparing it with the template, and then hypothesizes a more likely motion vector. This procedure, known as gradient descent optimization, progressively directs the search towards the likeliest match. Its aim is, in technical terms, to locate the local minimum of the error function.


The core idea is that the method attempts to reduce the error at each step, so as to improve the probability of finding a match. Every successive hypothesis is essentially a probe. The following movie clip visualizes the process of searching for a good match.
The value of the algorithm does not only lie in its practical efficacy but also in the style of thinking which it manifests. The practical and aesthetic aspects are closely interconnected. The result of every step typically contains some error, but the method is capable of measuring the error and refining its hypothesis in the next iteration. The intelligence and beauty of the algorithm does not consist in its immunity from error, but in its ability to identify the current error and use it to generate a refined hypothesis in the next step. Knowledge essentially grows out of an encounter with error.[3]