About
Theorem 8.1 is a 3-channel video projection installation exploring the intersection of art and mathematics. It investigates the artistic possibilities of the mathematical concept of orthogonal projection.
Given a set of digital images (the "dictionary"), orthogonal projection decomposes any source image into a weighted sum of those dictionary images. The elements of the dictionary are brightened or darkened by definite amounts so that their mixture approximates as closely as possible the source image.
Orthogonal projection is used in many practical digital signal processing applications, for instance to extract information from incomplete data or to reduce the complexity of high-dimensional data. The aim of this project is to open up this technological black box, to foreground the computational process involved, and to experiment with its artistic possibilities. The mathematical concept is investigated not as a practical tool but as an end in itself.
A fixed dictionary of still images from the film Alphaville (Jean-Luc Godard, 1965) is first selected. Then four disjoint sets of 30 images are extracted from this dictionary. Every image in the movie is then orthogonally projected onto each of the four sets of frames.
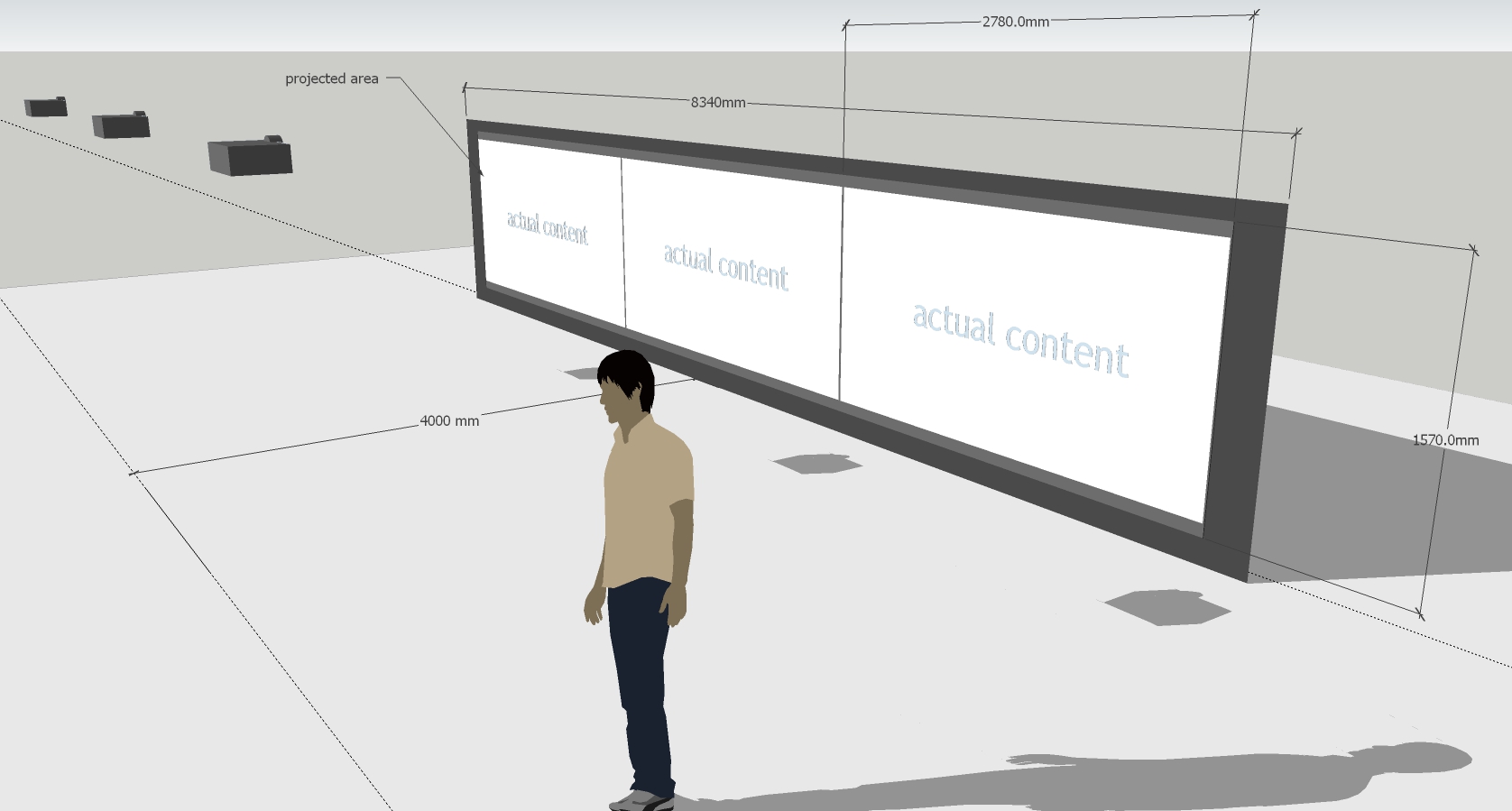
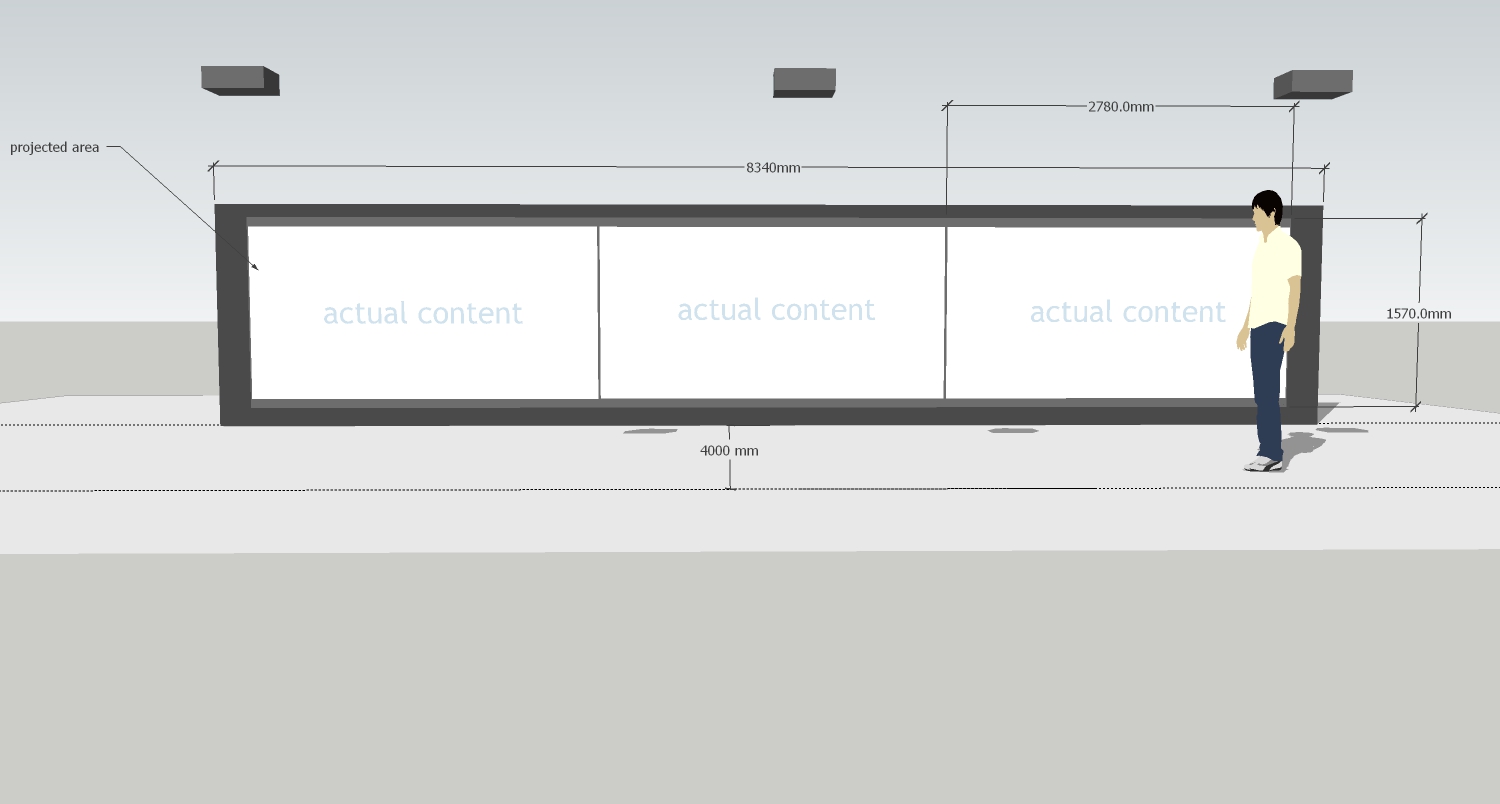
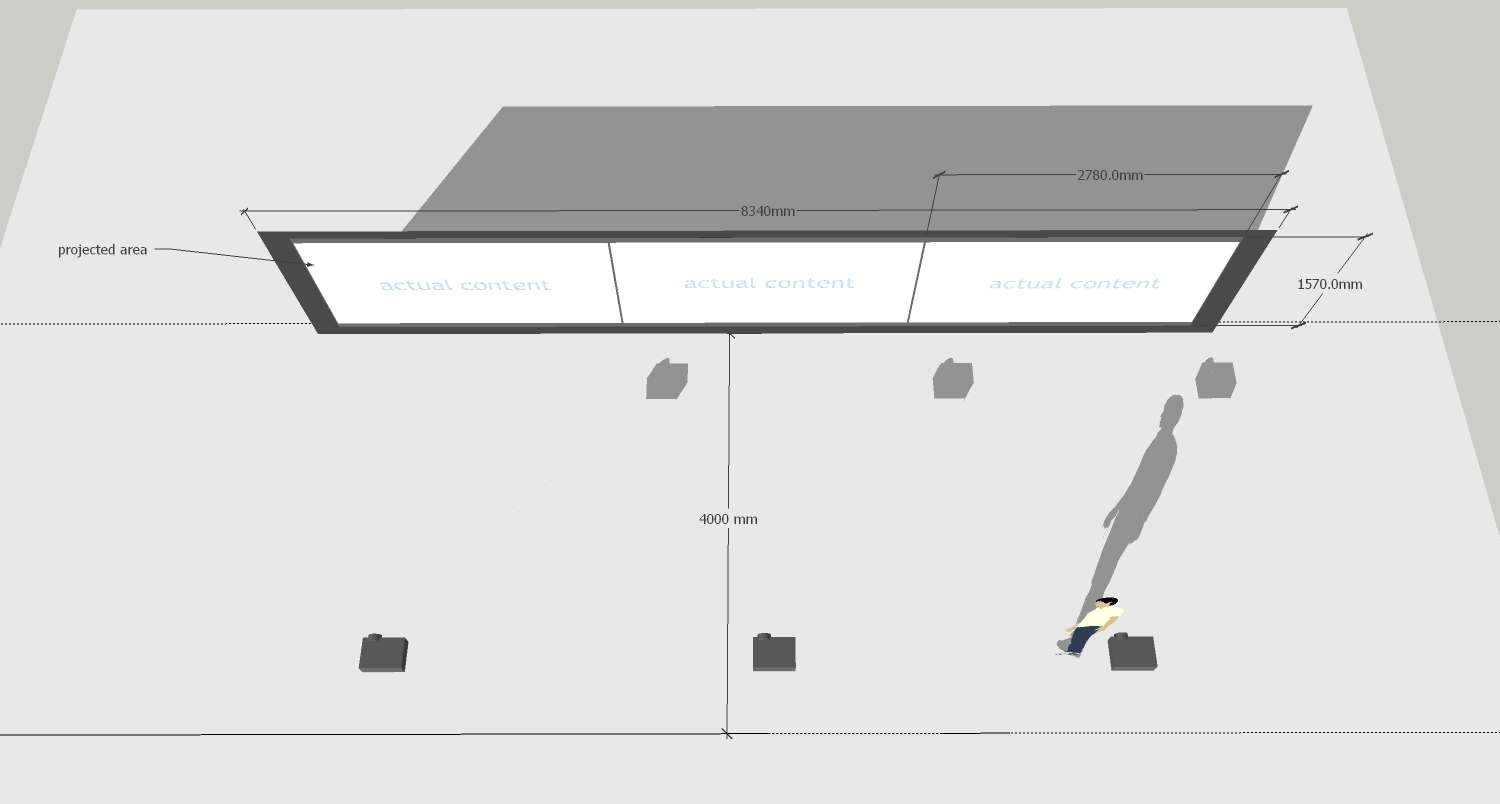
The installation consists of three video projection channels. In the center channel, the full original movie is shown in chronological order together with the four reconstructions.
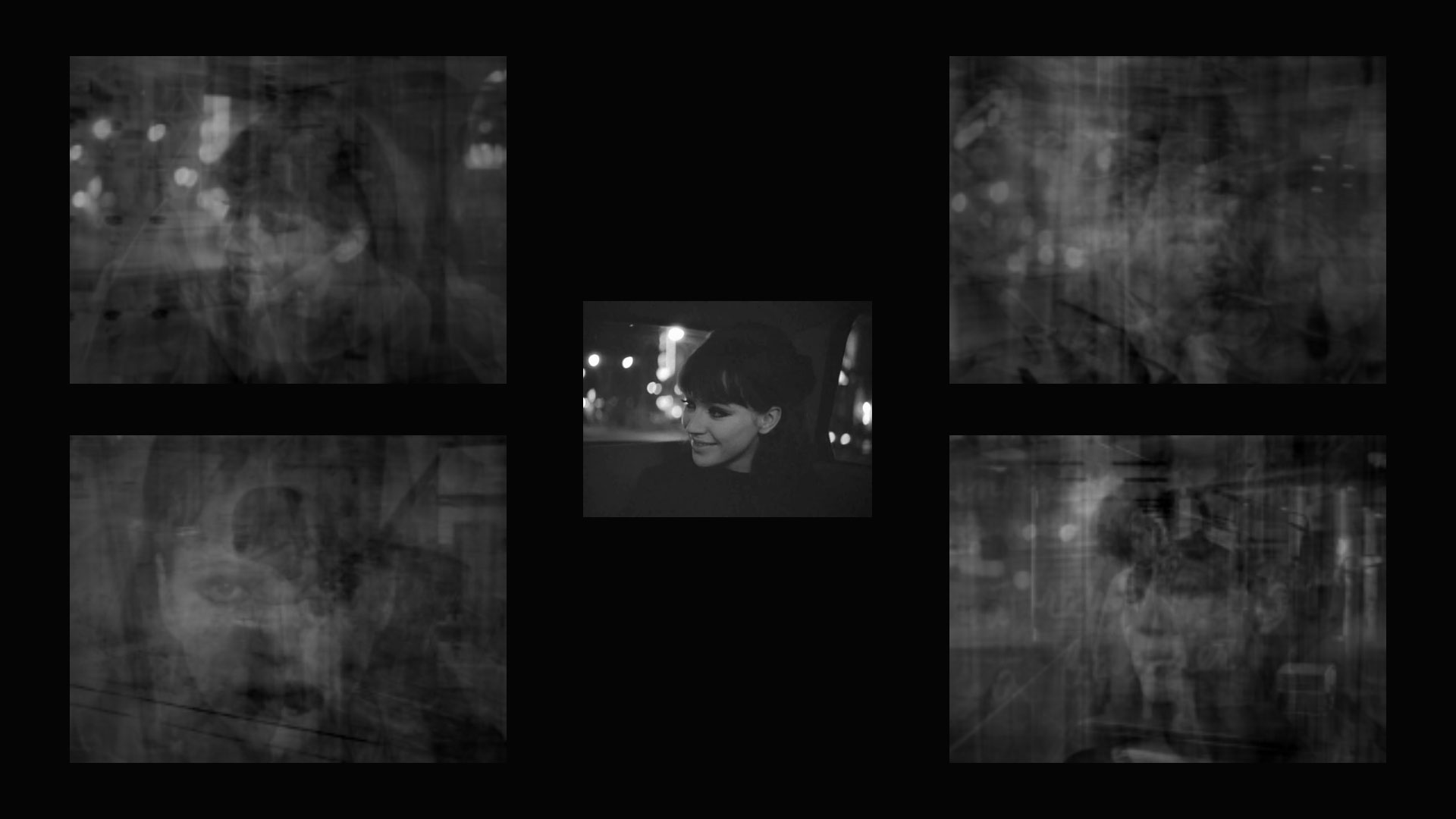
The left and right panels show the four sets of frames used in each the four decompositions.

The three channels are to be projected onto one single wall.

A detailed technical description, which explains the procedure employed in detail, is available here.
A video documentation describing and documenting the project can be found here .
Philosophical and social context of the work
Theorem 8.1 has been developed with social and cultural concerns in mind. The French philosopher Bernard Stiegler has noted that one of the most prevalent processes in contemporary culture is a widespread destruction of knowing-how. (Stiegler, 2010, p. 30.) According to Stiegler's analysis, every technical innovation makes possible an externalization of knowledge. For instance, the techniques of writing make possible an externalization of memory onto (e.g.) physical paper. Memory is materialized in some physical medium. In the process of externalizing ourselves, we also change ourselves. (Stiegler, 2015, p. 107.) There is a harmful aspect to these changes. As we come to rely more and more on technological exteriorizations, such as for instance computational media, artists lose more and more knowledge. (Stieger, 2015, p. 127.) In particular, we no longer know how to do things. For instance, a graphic designer can emboss a digital image using a software package like Photoshop with a click of the mouse. It is only slightly more difficult to assemble ("stitch") a set of photographs into large panoramas. New technologies appear to augment our capacities for doing things, but the supposedly competent user does not need to understand the algorithms that work behind the scenes to make these outcomes possible. As a result, the artist who uses the software is under the illusion that s/he knows how to emboss images or how to create panoramic images, but in fact has no conception of what these procedures actually involve. The artist dissociates her/himself from the mathematical foundation of her/his own tools, which become black boxes. This ignorance masquerading as knowledge prevails in the modern world. Stiegler describes this destruction of knowledge as a process of de- skilling whose outcome is "systematic stupidity" (Stiegler, 2010, p. 45.) We believe that Stiegler's diagnosis accurately and persuasively captures a crucially important aspect of our contemporary predicament as citizens and artists.
What can artists do to address this situation? One possible direction involves a practice of experimental exploration at the intersection of art and computational mathematics. This practice must satisfy two constraints. First of all, the artist must open at least one technological black box. The artist, often in collaboration with a scientist, chooses one or more computational technologies and acquires at least a basic theoretical knowledge and practical knowledge (knowing-how) of those technologies. The artist thus refuses to use technologies without actually understanding them. Instead of rejecting technology, the artist engages critically and reflectively with it. By proceeding in this way, the artist works to overcome the stupidity that Stiegler diagnoses. In Theorem 8, for instance, the artist chose to explore the concept of orthogonal projection, an idea that has been applied, for instance, in compute vision algorithms.
Secondly, the artist must not use this technology for some instrumental purpose, such as surveillance, face recognition, or image compression. Rather, the artist must investigate possible ways of connecting the abstract mathematical concepts that undergird this technology to concrete visual (or otherwise perceptible) experiences and diverse subject positionings. This critical investigation becomes an end in itself. The artist does not aim to achieve a practical end but rather to explore the intrinsic possibilities and limitations of the technology and its relation to the field of the visible. Possibly in collaboration with a scientist, the artist develops a research direction based on definite and systematic questions that arise in part from a mathematical or scientific framework. The questions take the following general form: What are the possible ways of relating the mathematical concepts that undergird this technology with perceptual experiences, and what are the tensions or limitations of these relations? These questions must orient her/his experimental art practice.
_____________
References
Lay, D. C. (2011). Linear Algebra and Its Applications, 4th edition. Pearson.
Stiegler, B. (2010). For a New Critique of Political Economy, D. Ross (Trans.), Cambridge:
Polity Press.
Stiegler, B. (2015). States of Shock, D. Ross (Trans.), Cambridge: Polity Press.