Technical description
Factorization
A frequently used method to understand a given dataset is to select a set of dominant (representative, prototypical) latent components. Every entry in the dataset is to be approximately reconstructed as a weighted mixture ("linear combination") of those latent components. We will refer to any collection of latent components associated with a specific dataset as a “dictionary”. We will refer to any procedure for reconstructing a dataset in the manner described as a “factorization method”.
In this work, the dataset consists of all the frames in a digitized version of the film Alphaville. The dictionary consists of a proper subset of those frames.
We now introduce some basic notions. A grayscale image consisting of n pixels is a vector in ℝn. Images correspond to points in the unit hypercube [0, 1]n within ℝn. Any set of k linearly independent images (i.e., any dictionary) spans a k-dimensional subspace of ℝn. A dictionary of k elements is to be represented as an n x k matrix W. The reconstruction F of any frame f by means of dictionary W can be represented as a vector v of weights or “activation coefficients”. The ith element in v represents the weight that the ith frame in W has in F. In other words, F = W v.
A factorization method involves, first of all, a procedure for constructing W and, secondly, a procedure for reconstructing any f as weighted combinations of entries in W ( i.e., a procedure for computing v ).
There are many possible factorization methods. Some methods, such as for instance Principal Component Analysis, allow both the latent components (dictionary elements) and the activation weights to contain negative values. But then the latent components and their weights have no physical meaning. Suppose that the value (brightness) of any grayscale pixel is represented as a real number in the interval [0, 1], where 0 represents white and 1 represents black. In this context, the notion of an image with negative values, i.e., with pixels lighter than white, has no physical content. Any such “frame” is a purely formal entity and cannot be easily understood or immediately visualized. Moreover, the application of a negative coefficient to a frame does not correspond to any physical operation. Another problem is that the linear combination of elements in the dictionary is not in general inside the unit hypercube in ℝn.
The algorithm used in this project is designed to avoid these shortcomings. It decomposes every frame using dictionaries of non-negative components and non-negative activation weights.
Procedure
The procedure involves two steps, a dictionary selection step and a frame reconstruction step.
1. Dictionary selection
The first step selects a set of images suitable to function as dictionary entries. We wish those entries to be extreme data points, i.e., points that reside on or near the convex hull of the point data set. To accomplish this aim, we use the Simplex Volume Maximization (SiVM) algorithm proposed by Thurau, Kersting and Bauckhage.
1.1 Terminology
It is sometimes useful to speak about objects of arbitrary dimensions, in order to make statements of a general nature about them. This generalization is often accomplished by identifying kinds of objects of different dimensions that are analogous to one another. For instance, a tetrahedron is the simplest instance of an ordinary polyhedron in three-dimensional space; we can consider a triangle, a segment, and a point as two-, one-, and zero-dimensional analogues of a tetrahedron. Analogues of a tetrahedron also exist in higher dimensions. These objects are all designated as simplexes.
The concept of a simplex (or hypertetrahedron) generalizes the concept of a tetrahedron to arbitrary dimensions. A (k - 1) simplex in k-dimensional space is the convex hull of k -1 linearly independent points.
The standard n-simplex is the simplex whose vertices are the n + 1 vectors in the standard basis for ℝn+1. For instance, the standard 1-simplex is the segment whose vertices are the points (1,0) and (0,1). The standard 2-simplex is the triangle whose vertices are the points (1,0,0), (0,1,0), and (0,0,1).
An important property of a simplex is its volume. While “volume” in ordinary language describes properties of three-dimensional objects, the same word is used with a more general meaning when speaking of simplexes. The volume of a 1-simplex is its length. The volume of a 2-simplex is its area. The volume of a 3-simplex corresponds to the ordinary notion of volume. Again, higher dimensional analogues of the concept of volume also exist.
It is important to bear in mind that this concept of volume is extremely general, and encompasses a family of different measures, one for each dimension (length, area, etc.). It is nonetheless useful, when formulating a general algorithm, to speak of volume in this abstract sense. This linguistic convention allows us to speak of the volume of a simplex, and by that mean the length of a segment, the area of a triangle, the volume of a tetrahedron, etc., without having to be more specific.
1.2 Motivation
This section motivates the design of the SiVM algorithm.
Any finite set C containing m non-negative vectors in ℝn always lies in a convex polyhedral cone Ω, namely, the convex hull of the set of rays whose directions are determined by the vectors in C.
There exists a subset D ⊆ C such that Ω is the smallest convex cone containing D.
The convex hull ΩC is the set of all non-negative linear combinations of points in C. Points not in ΩC are approximated by points in ΩC.
We want to find a subset D ⊆ C of k elements such that we approximate every point in C by a point in ΩD.
Given C and k, what is the best choice of D? The answer is the subset of C that maximizes the finite volume of ΩD, i.e., the volume of ΩD ∩ Sn-1, where Sn-1 is the unit sphere in ℝn. (The volume of a cone is infinite, so we cannot literally speak of maximizing the volume. Instead, when we speak of maximizing the volume of a cone, we consider the volume of the intersection of the cone with the unit hypersphere.)
The basic idea is best illustrated taking C to consist of a set of points in ℝ2.
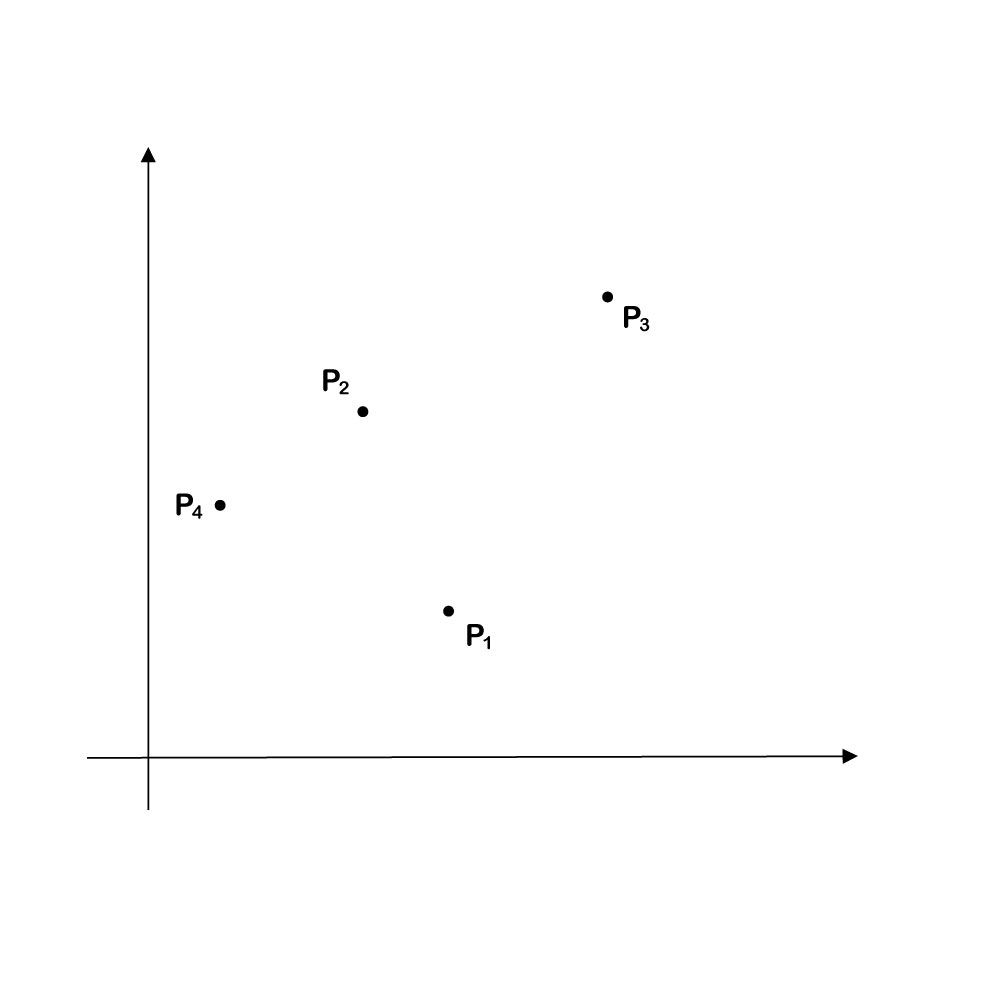
We wish to approximate every point in C as a non-negative combination of a subset D ⊆ C consisting of two points (vectors). Suppose we select D as containing points P1 and P2. In that case, we can perfectly approximate point P3 as a non-negative linear combination of P1 and P2.

The problem is that the best approximation of P4 using P1 and P2 will be very far from P4.
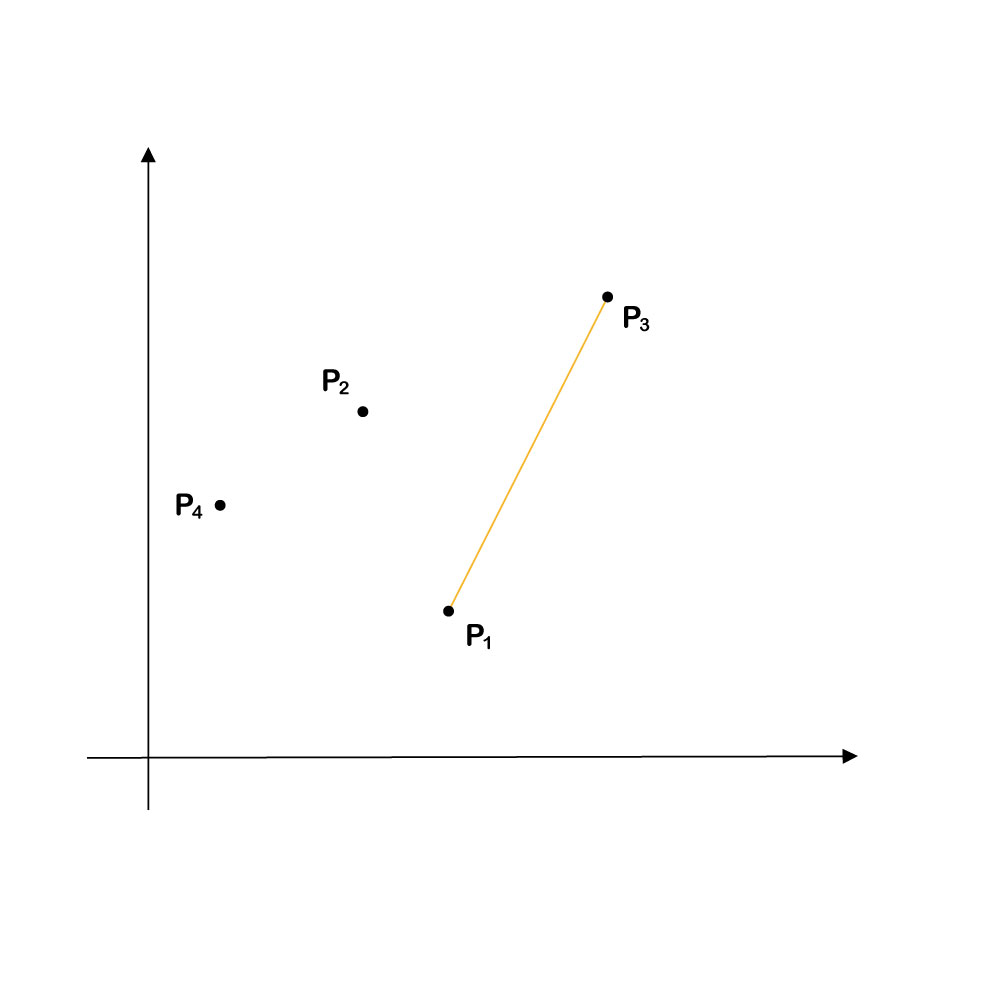
Points P1 and P4 make for a superior choice. All other points in C lie within the cone determined by those two points (the shaded area in the diagram below). All can be accurately reconstructed as a nonnegative linear combination of P1 and P4. This choice of D maximizes the volume of ΩD. The selected points can be considered to be the most representative of the set.

How do we select representative points from a given set? One plausible suggestion (still referring to our example) would be to identify the two points that determine the (nonstandard) 1-simplex with the greatest volume. This suggestion, however, does not work. In the example at hand, the points would be points P1 and P3. The simplex here is a segment, and the volume of this simplex is its length. Although the two points determine the simplex with the greatest possible volume (the longest segment joining any two pairs of points in C), they are not the points that we want. This choice does not correspond to the ΩD with maximum volume.
We will obtain the result we want if we first pre-process the data, as follows. Define the pullback transformation as the operation of 1-normalizing every vector (dividing every entry in a vector by the 1-norm of that vector). This procedure maps every point associated with a vector in C to a unique point within the (n-1) standard simplex. It is illustrated in the following diagrams:
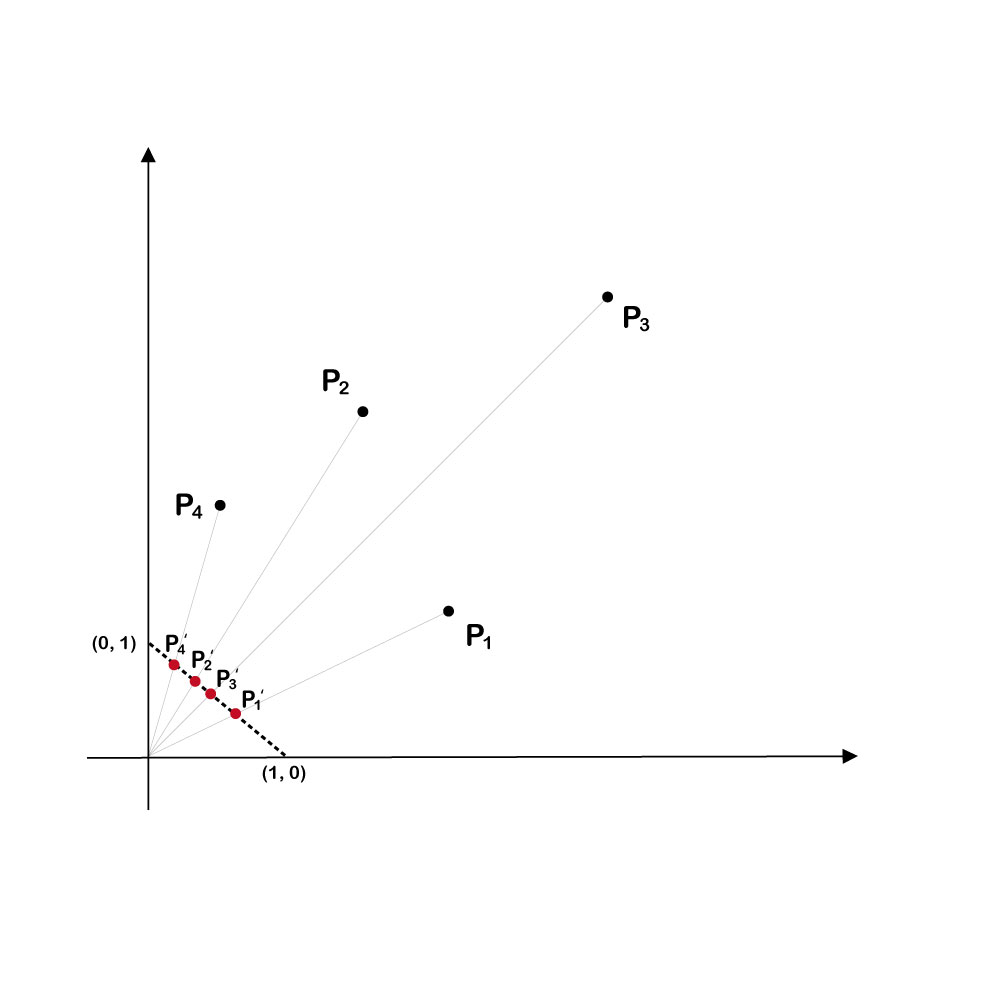
The cone ΩD projects on the bounded convex subset F of the standard simplex. It can be shown that, if our data has been so projected, maximizing vol (ΩD ∩ Sn-1) approximately amounts to maximizing vol (F).
In this example, the two points that determine the simplex with the largest volume are P1' and P4', the projections of P1 and P4. They determine the longest segment of any pair of projected points. These are exactly the points that we wish to select.
Note that for illustrative purposes, we have considered the situation where we aim to choose two representative points in ℝ2. In the actual production of this project, however, we want choose m representative points in ℝn, where n is the number of pixels of an image, m is the number of elements in the dictionary, and m << n.
1.3 SiVM Algorithim
All data is pre-processed using the pullback transformation described in the previous section.
The algorithm involves greedy stochastic hill climbing. It receives as input a database S of vectors (the frames in the chosen movie) and a desired number k of prototypical frames. It outputs a set D containing k prototypical frames. The elements in S reside in (the unit hypercube in) ℝn, a vector space naturally endowed with a distance measure, the Euclidean distance.
The algorithm first initializes D as follows: pick a random frame P1 in S, then find the frame P2 in S that is furthest from P1, and then the frame P3 that is furthest from P2. Select P3 as the first entry in D.
After initialization, the procedure iterates over every vector si in S not already in D, and computes the volume of the simplex 𝓦 spanned by the union of si and the vectors already in D. The vector si that yields the maximum volume is then added to D. This procedure is repeated until D contains k representative frames.
To speed up execution of the algorithm, we first preselect a proper subset of the frames in Alphaville. This subset consists of all frames that are local peaks in the Entropic Envelope of the movie (a description of the entropic envelope concept can be found here). The preselection is then fed into the SiVM algorithm, which outputs the final selection D.
From this selection, we manually form one or more dictionaries to be used in the next step. Every dictionary matrix W contains a proper subset of the frames in D.
2. Frame reconstruction
The second step reconstructs every frame in the source movie using the dictionary W identified in the previous step.
The movie is divided into sequences (ordered sets of consecutive frames) of uniform length 𝓁. Each sequence is associated with an n x 𝓁 matrix V whose columns represent the frames in the sequence. V is then reconstructed using a Non-Negative Matrix Factorization (NNMF) algorithm.
NNMF is a family of algorithms that receive a matrix Vn x m of non-negative data and approximately decomposes it into two matrices Wn x k and Hk x m, both of which are also non-negative. The matrix W can be interpreted as containing k basis vectors (i.e., a lexicon) and H as containing the mixing coefficients or activation weights on those vectors.
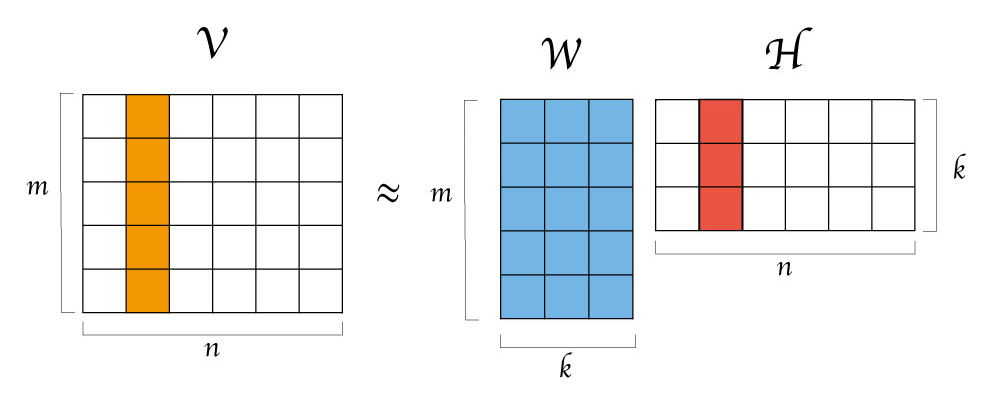
In the above figure, the image represented by the second column in the input matrix V is approximately reconstructed as a linear combination of all columns in W. The reconstruction is accomplished by multiplying every column vector in W by the corresponding entry in the second column of H. The resulting weighted vectors are added together to produce the final reconstruction of the input image.
Most versions of the NNMF algorithm provide ways to compute both the basis matrix W and the activation weight matrix H.
In the present implementation, we do not need to compute W. Every column of W is one of the frames selected in step one. We use the algorithm only to obtain the activation coefficients.
For each matrix V and each dictionary W, we compute a k x 𝓁 coefficient matrix H such that the Frobenius norm || V – WH || is minimized, subject to the constraint that H is non-negative. We use the standard minimization algorithm proposed by Lee and Seung, but we fix W and only update the entries in H iteratively. We then obtain the matrix of reconstructed images V’ = WH.
In the final artwork, we split the dictionary obtained in step two into four distinct bases W1, W2, W3, and W4. We then decompose every frame matrix V using each of the four bases, to obtain four coefficient matrices H1, H2, H3, and H4. We display the four reconstructions. We also show the individually weighted basis elements in order to highlight their individual contributions.
_____________

